Click Here to Download Source Code
Customize your security testing with SmeegeScrape.py! It's a simple python script to scrape text from various sources including local files and web pages, and turn the text into a custom word list. A customized word list has many uses, from web application testing to password cracking, having a specific set of words to use against a target can increase efficiency and effectiveness during a penetration test. I realize there are other text scrapers publicly available however I feel this script is simple, efficient, and specific enough to warrant its own release. This script is able to read almost any file which has cleartext in it that python can open. I have also included support for file formats such as pdf, html, docx, and pptx.

Usage:
SmeegeScrape.py {-f file | -d directory | -u web_url | -l url_list_file} [-o output_filename] [-s] [-i] [-min #] [-max #]
One of the following input types is required:(-f filename), (-d directory), (-u web_url), (-l url_list_file)
| -h, --help | show this help message and exit |
| -f LOCALFILE, --localFile LOCALFILE | Specify a local file to scrape |
| -d DIRECTORY, --fileDirectory DIRECTORY | Specify a directory to scrape the inside files |
| -u URL, --webUrl URL | Specify a url to scrape page content (correct format: http(s)://smeegesec.com) |
| -l URL_LIST_FILE, --webList URL_LIST_FILE | Specify a text file with a list of URLs to scrape (separated by newline) |
| -o FILENAME, --outputFile FILENAME | Specify output filename (default: smeegescrape_out.txt) |
| -i, --integers | Remove integers [0-9] from all output |
| -s, --specials | Remove special characters from all output |
| -min # | Specify the minimum length for all words in output |
| -max # | Specify the maximum length for all words in output |
Scraping a local file:
SmeegeScrape.py -f Test-File.txt
This is a sample text file with different text.
This file could be different filetypes including html, pdf, powerpoint, docx, etc.
Anything which can be read in as cleartext can be scraped.
I hope you enjoy SmeegeScrape, feel free to comment if you like it!
enjoy
comment
powerpoint,
feel
text
is
sample
as
including
file
in
if
different
pdf,
to
read
which
you
SmeegeScrape,
hope
be
Anything
This
html,
cleartext
text.
free
it!
with
a
I
like
filetypes
could
scraped.
can
many
docx,
etc.
Each word is separated by a newline. The options -i and -s can be used to remove any integers or special characters found. Also, the -min and -max arguments can be used to specify desired word length.
Scraping a web page:
SmeegeScrape.py -u http://www.smeegesec.com -si
To scrape web pages we use the python urllib2 module. The format of the url is checked via regex and it must be in the correct format (e.g. http(s)://smeegesec.com)

Scraping multiple files from a directory:
SmeegeScrape.py -d test\ -si -min 5 -max 12
The screen output shows each file which was scraped, the total number of unique words found based on the user's desired options, and the output filename.

Scraping multiple URLs:
SmeegeScrape.py -l weblist.txt -si -min 6 -max 10
The -l option takes in a list of web urls from a text file and scrapes each url. Each scraped URL is displayed on the screen as well as a total number of words scraped.


This weblist option is excellent to use with Burp Suite to scrape an entire site. To do this, proxy your web traffic through Burp and discover as much content on the target site as you can (spidering, manual discovery, dictionary attack on directories/files, etc.). After the discovery phase, right click on the target in the site map and select the option "Copy URLs in this host" from the drop down list. In this instance for even a small blog like mine over 300 URLs were copied. Depending on the size of the site the scraping could take a little while, be patient!
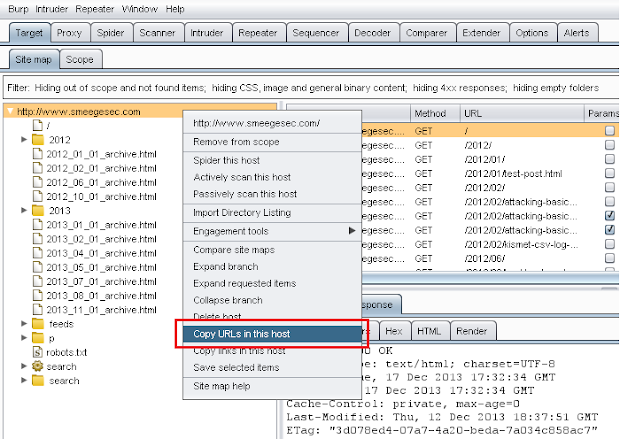
Now just paste the URLs into a text file and run that as input with the -l option.
SmeegeScrape.py -l SmeegeScrape-Burp-URLs.txt -si -min 6 -max 12

So very easily we just scraped an entire site for words with specific attributes (length and character set) that we want.
As you can see there are many different possibilities with this script. I tried to make it as accurate as possible however sometimes the script depends on modules such as nltk, docx, etc. which may not always work correctly. In situations like this where the script is unable to read a certain file format, I would suggest trying to convert it to a more readable file type or copy/paste the text to a text file which can always be scraped.
The custom word list dictionaries you create are up to your imagination so have fun with it! This script could also be easily modified to extract phrases or sentences which could be used with password cracking passphrases. Here are a couple examples I made:
Holy Bible King James Version of 1611:
SmeegeScrape.py -f HolyBibleDocx.docx -si -min 6 -max 12 -o HolyBible_scraped.txt
Testament
Esther
Obadiah
parents
strife
fearful
passage
deathmark
continuance
children
nought
remove
traffic
Malachi
Haggai
Shakespeare's Romeo and Juliet:
SmeegeScrape.py -u http://shakespeare.mit.edu/romeo_juliet/full.html -si -min 6 -max 12 -o romeo_juliet_scraped.txt
Juliet
Entire
Shakespeare
heartless
Benvolio
manage
coward
several
houses
Citizen
partisans
Capulets
CAPULET
crutch
households
Feel free to share your scraped lists or ideas on useful content to scrape. Comments and suggestions welcome, enjoy!



Excellent! I've been using two other scripts but I think am going to switch to this one.
ReplyDelete